AI Verse démocratise l’accès aux datasets

Avec sa solution SaaS, AI Verse démocratise l’accès aux datasets labélisés pour les PME / PMI et leur permet d’entraîner des applications innovantes en vision artificielle à une fraction du coût actuel. Benoît Morisset, CEO d’AI Verse, nous en dit plus.
Dans le monde de l’IA, quels sont le métier et le positionnement d’AI Verse ?
AI Verse est une start-up Deep Tech B2B, incubée à l’INRIA pendant 18 mois et qui a vu le jour en 2020. Nous avons développé une technologie qui produit de manière automatisée des images synthétiques optimisées pour l’entraînement des réseaux de Deep Learning. Nous avons conçu un système entièrement self-service qui permet à des entreprises de toute taille de générer elles-mêmes leurs datasets pour diverses applications en vision artificielle : smartphones, réalité augmentée, robots, assistants digitaux, caméras de surveillance, véhicules autonomes…
La génération d’un dataset entièrement labellisé peut maintenant être faite directement par l’ingénieur CV /ML qui en a besoin, en quelques heures et pour une fraction du coût de la création d’un dataset d’images réelles. Aujourd’hui, AI Verse regroupe une douzaine de personnes. Nous avons levé 2,5 millions d’euros en amorçage en septembre 2021 pour accélérer notre développement.
Concrètement, quels sont les enjeux et besoins auxquels vous répondez ?
Les caméras se multiplient partout dans nos vies. Il est primordial que tous les systèmes qui en sont dotés comprennent de mieux en mieux le contenu des images qu’ils capturent. Cette compréhension est indispensable pour rendre les systèmes artificiels plus autonomes, plus efficaces, plus sûrs et plus pertinents dans leurs interactions avec les humains. Cette compréhension des images passe par l’entraînement de réseaux de Deep Learning. Si aujourd’hui les modèles sont performants et accessibles sur étagère, le point bloquant est toujours l’accès aux données d’entraînement pour divers cas d’usage. Dans la plupart des cas, ces données sont tout simplement impossibles à acquérir. Si, par exemple, vous voulez entraîner un robot aspirateur à détecter la chute d’une personne chez elle, où trouverez-vous les 500 000 images intégrant toutes les variations nécessaires pour généraliser le concept de chute, quelles que soient les variations de l’éclairage, de l’âge, du sexe et de la morphologie de la personne au sol, de sa posture particulière, de l’ameublement et de la décoration de la pièce ? Et si ces images peuvent être collectées, il faudra encore les labelliser une à une manuellement dans un processus onéreux qui nécessite des mois de travail.
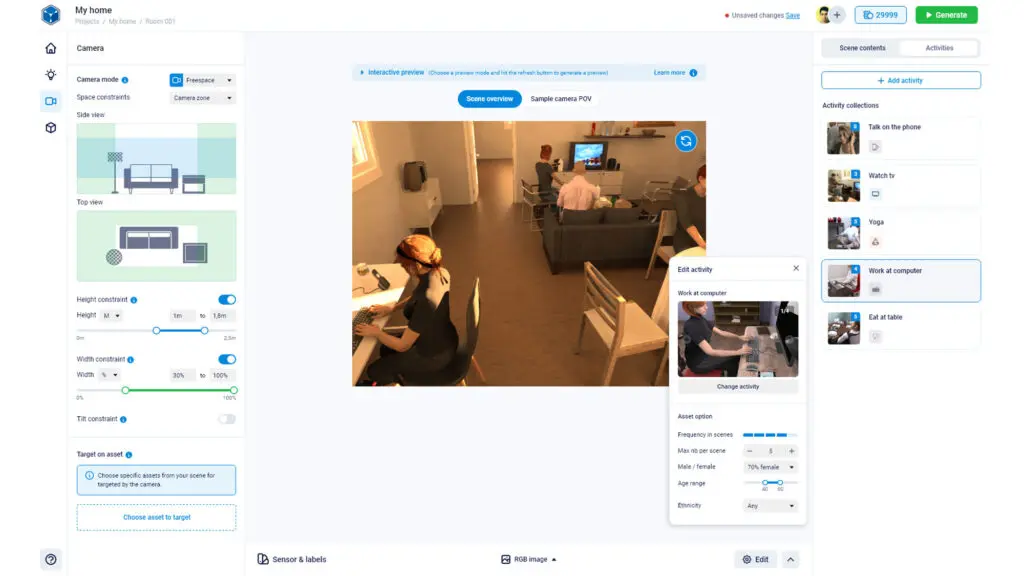
C’est à cette difficulté bloquante pour l’innovation en vision artificielle que nous répondons. Nous rendons la construction d’un dataset rapide, simple et configurable à volonté. Ce processus ne requiert plus des équipes entières ni de recours à la sous-traitance. La construction d’un dataset devient ainsi une tâche réalisée en toute autonomie par l’ingénieur qui a besoin d’images à partir d’un frontend sophistiqué qui lui permet de configurer lui-même son cas d’usage et le type d’images dont il a besoin.
Et dans cette démarche, quelle est la proposition de valeur d’AI Verse ?
Microsoft a développé un dataset très connu, COCO (Common Objects in Context), qui inclut des images réelles labellisées manuellement. Il a fallu à Microsoft plus de 70 000 heures de travail afin de labelliser ces 200 000 images. Ce temps n’inclut d’ailleurs pas la collecte et la gestion de ces bases d’images volumineuses qui posent aussi de vrais challenges d’infrastructure et donc des coûts supplémentaires. En 2020 et 2021, une campagne d’évaluation intensive réalisée en collaboration avec l’INRIA a montré qu’AI Verse est capable de produire un dataset aux propriétés et aux performances d’entraînement équivalentes à COCO en seulement quelques heures de calcul sur le cloud et ce, sans avoir à faire intervenir une ressource.
La création des datasets représente les dépenses les plus élevées dans le développement d’applications de vision artificielle. Nous changeons la donne en transformant les datasets en du consommable accessible rapidement et pour un coût divisé par plusieurs ordres de grandeur.
Dans cette démarche, quels sont vos principaux enjeux ?
Nous avons, d’abord, un enjeu d’éducation et d’évangélisation sur l’utilisation des images synthétiques pour l’entraînement de modèles de Deep Learning : est-ce que les images synthétiques marchent aussi bien que des images réelles ? comment gérez-vous le problème du « reality gap » ? est-ce qu’un entraînement fait à partir d’images synthétiques généralise bien ? …
Notre réponse peut paraître contre-intuitive, mais repose sur plus de deux ans de comparaison d’entraînements de divers modèles, pour diverses tâches, réalisés à partir d’images réelles et à partir d’images synthétiques. Pour nous, les images réelles ne sont pas le bon matériau pour entraîner des réseaux : elles sont trop difficiles et coûteuses à acquérir et à labelliser. Les labels manuels sont très limités et souvent imprécis. Les datasets sont trop rigides et impossibles à modifier. Par exemple, on ne peut plus modifier l’éclairage des scènes ou changer les paramètres de la caméra une fois les images acquises. D’autre part, une fois le dataset construit, il est impossible de connaître les biais inhérents au dataset : combien d’images sont prises avec le soleil faisant face à la caméra ? Combien d’images incluent des objets transparents ? Combien d’hommes, de femmes, ou d’enfants ? Combien de personnes habillées en foncé ou en couleurs vives ? … Toutes ces mesures ne peuvent pas être réalisées à partir d’images réelles. Les distributions de l’ensemble des paramètres ne sont pas maîtrisées et restent inconnues. Ces déséquilibres impactent négativement la qualité des entraînements. Notre campagne d’évaluation nous a enseigné deux choses : le « reality gap » existe aussi entre deux datasets différents d’images réelles, et ce qui compte, ce n’est pas l’hyper-réalisme des images, mais la meilleure couverture et distribution possible de tous les paramètres de l’espace d’apprentissage.
Contrairement aux images réelles, notre système permet à l’utilisateur de contrôler et de configurer l’ensemble des paramètres participant à la création des scènes 3D et au rendu des images de synthèse. Les images de synthèse sont donc parfaitement configurables et les datasets optimisables. C’est pour cette raison que pour tous les tests que nous avons menés, nos images de synthèse ont toujours au moins égalé les images réelles, en les dépassant le plus souvent. Comme le moteur construit lui-même ses scènes et ses images, il peut générer toute une variété de labels impossibles à produire manuellement comme la position 3D des articulations des acteurs, les boîtes englobantes 3D de tous les objets de l’image, des segmentations « pixel-perfect » sans biais…
Sur ce marché, comment vous projetez-vous ? Quelles sont les prochaines étapes pour AI Verse ?
La première version de notre produit accessible en ligne et en mode self-service couvrira les cas d’usage que l’on retrouve dans des environnements de type « Household ». Il s’adresse en priorité aux applications liées à la réalité augmentée, la robotique personnelle, à la surveillance / sécurité, aux robots aspirateurs, aux smart TV… Nous étendrons périodiquement notre solution à d’autres marchés en ajoutant d’autres environnements comme les gares, les aéroports, les usines, les supermarchés… Nous allons également préparer une levée de fonds (série A) courant 2023.
Enfin, à ce stade, nous avons déjà une version beta que nous souhaiterions faire évaluer par des entreprises intéressées par une collaboration avec nous. Avis aux amateurs, n’hésitez pas à me contacter (https://www.ai-verse.com ) !