
Les processus quantiques : la recherche fondamentale vers l’ingénierie

Alors que de nombreux processeurs fondés sur des technologies distinctes sont progressivement mis à la disposition des acteurs académiques et industriels, la construction d’un véritable écosystème du calcul quantique débute seulement. Une approche globale mêlant l’applicatif, le développement logiciel et le hardware quantique et classique est nécessaire pour utiliser ces ressources de façon optimale.
De nombreuses plateformes quantiques opèrent déjà dans des régimes qui sont hors de portée des supercalculateurs classiques. Citons par exemple les atomes neutres, qui ont démontré leur supériorité sur des problèmes de simulation quantique [Schreiber, Scholl], les qubits supraconducteurs et les circuits aléatoires désormais célèbres depuis les expériences de Google [Arute] ou les plateformes photoniques et le boson sampling [Zhong]. Ces expériences constituent des jalons fondamentaux dans la course à l’ordinateur quantique, mais elles concernent des problèmes académiques sans application industrielle directe. Pour rendre ces développements utiles, il faut transformer ces prototypes de recherche fondamentale en outils industriels.
Penser le développement de l’industrie quantique
Ce changement d’utilisation requiert une plus grande fiabilité et une plus grande reproductibilité des calculs réalisés. Pour ce faire, il est nécessaire de transiger sur le degré d’ouverture de ces plateformes, au profit d’une plus grande robustesse ; et la modularité et la facilité de maintenance sont à privilégier. Cette approche diffère grandement du mode de fonctionnement académique, dans lequel les expériences sont traditionnellement construites pour être évolutives et pouvoir être transformées facilement, avec une conception mobile. Au-delà de l’industrialisation de la conception des processeurs et de l’amélioration nécessaire des métriques fondamentales qui déterminent leurs performances (fidélité des opérations quantiques, taux de répétition, nombre de qubits), il est nécessaire de penser le développement de l’industrie quantique émergente à un niveau global.
Des algorithmes hybrides impliquant des ressources classiques et quantiques
On compare souvent les débuts de l’informatique quantique aux débuts de l’informatique classique. Mais cette comparaison a des limites, dans la mesure où l’informatique quantique peut s’appuyer sur les infrastructures et les pratiques développées pour le calcul haute performance classique et le web. Le premier levier classique qui peut être mis à profit correspond au développement de l’accès via le cloud aux processeurs quantiques. Ce mode d’accès permet aux utilisateurs de comprendre plus précisément le hardware et aux développeurs de hardware de mieux comprendre les attentes des utilisateurs.
En 2020, IBM déclarait déjà plus de 200 000 utilisateurs avec plus de 70 milliards de circuits utilisés via leur cloud, ayant généré plus de 200 articles scientifiques. Ce fonctionnement hybride facilite aussi une implémentation optimale des algorithmes variationnels, où le processeur quantique est utilisé pour créer un algorithme paramétrique optimisé par un processeur classique dans une boucle fermée.
“Des super-calculateurs hybrides, incorporant des éléments classiques et quantiques.”
Au-delà de ces algorithmes variationnels simples, pour lesquels le processeur classique se cantonne à un simple rôle d’optimiseur, on a pu récemment voir l’émergence de véritables algorithmes hybrides impliquant des procédures complexes du côté classique. On peut citer l’exemple récent des réseaux de neurones quantiques pour problèmes de graphe (quantum graph neural networks), qui intègrent au sein d’un réseau de neurones classique traditionnel un mécanisme d’agrégation de l’information calculé grâce un processeur quantique [Thabet]. Pour un tel algorithme, la collocation d’un processeur quantique avec des ressources de type GPU semble nécessaire pour limiter les coûts de transfert des données et atteindre des performances intéressantes.
Ces développements s’inscrivent dans la vision de supercalculateurs hybrides, incorporant des éléments classiques et quantiques. Ce mode de fonctionnement est au cœur de l’initiative européenne HPCQS, dont l’objectif est de déployer une infrastructure hybride de calcul haute performance couplée à des processeurs quantiques. On retrouve aussi cette vision hybride très marquée dans la stratégie d’entreprises comme Nvidia ou IBM. En plus d’être une chance pour un développement plus rapide, adosser les technologies quantiques émergentes aux infrastructures classiques est en fait une nécessité : il ne suffit pas avec le calcul quantique d’apporter de meilleures performances algorithmiques, il faut aussi faciliter l’intégration d’une composante quantique aux outils déjà utilisés par les industriels.
Un développement conjoint du logiciel et du hardware
L’informatique classique a vu le triomphe du développement logiciel indifférent au hardware. Cette philosophie est liée à la rapidité de développement des puissances de calcul pendant la phase 1980–2010. Les augmentations prévisibles de la capacité de calcul et de la mémoire ont rendu les innovations sur les architectures hardware très risquées. Même pour les calculs complexes exigeant des performances spécifiques, les avantages du passage à un hardware spécialisé pouvaient être rapidement éclipsés par la prochaine génération de hardware généraliste, dotée d’une capacité de calcul toujours plus grande. C’est ce qui a poussé la communauté vers des processeurs classiques les plus universels possible et le logiciel à se désolidariser progressivement du hardware.
Ce n’est plus le cas aujourd’hui, et il y a de plus en plus d’intérêt (par exemple en machine learning) à un développement joint entre le hardware et le software. Cela constitue une occasion unique pour le calcul quantique. Dans la période actuelle, où les processeurs quantiques sont bruités et imparfaits, il est tout à fait fondamental de procéder au développement algorithmique en ayant pleinement conscience des forces de chaque processeur, tout en essayant de limiter les impacts de ses limitations intrinsèques.
C’est cet argument qui a en partie motivé de nombreux acteurs du domaine comme IBM ou Google d’opter pour une approche dite full-stack, combinant le hardware et le développement logiciel. Le secteur a aussi assisté à plusieurs consolidations vers le full-stack avec les fusions d’Honeywell et de CQC, de Pasqal et de Qu&Co, ou de ColdQuanta et Super.tech. Ces rapprochements facilitent le développement d’algorithmes natifs, qui engendrent peu ou pas de surcoût à l’implémentation, qui devient alors plus directe et robuste.
Lire aussi : Pasqal : le quantique, une révolution à portée de main pour toutes les industries !
Apprentissage automatique quantique pour la gestion du réseau haute-tension
Exemple d’algorithme issu d’une approche de conception mêlant les considérations hardware et applicatives, l’automatisation de la gestion du réseau haute tension est devenue une priorité pour les gestionnaires de réseau de transport d’électricité. La complexité du réseau (énergies intermittentes, flux transfrontaliers) associée à de multiples interdépendances rend la tâche difficile. Une approche prometteuse est d’avoir des automates locaux, qui sont chacun en charge de l’équilibre pour un sous-ensemble du réseau (voir figure ci-dessous). Cependant, la détermination de ces sous-ensembles relativement indépendants est une tâche difficile. L’utilisation des algorithmes d’apprentissage automatique sur graphes développés par Pasqal pourrait améliorer considérablement la qualité de la segmentation. Ces algorithmes ont été développés spécifiquement pour des processeurs quantiques à atomes neutres dont la géométrie du registre est reconfigurable, permettant ainsi un traitement naturel de données structurées sous la forme de graphes.
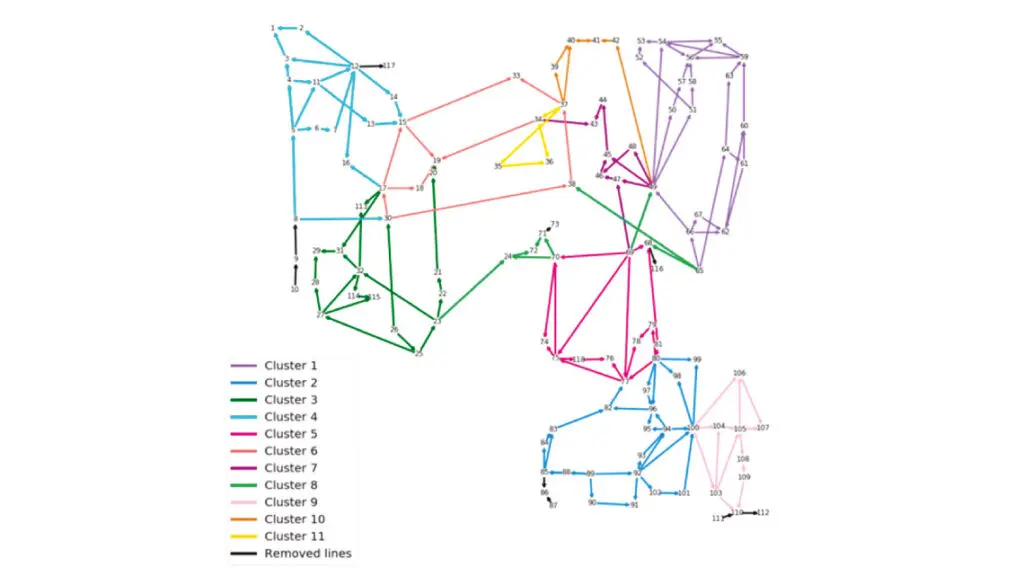
Avoir des points de comparaison pertinents
La cohabitation d’équipes d’algorithmiciens et de constructeurs de hardware a un autre avantage considérable en termes applicatifs. Les équipes théoriques peuvent travailler directement avec des clients sur des cas d’usage réels et confronter leurs algorithmes quantiques à l’état de l’art classique. En pratique, peu d’industriels se soucient des performances asymptotiques d’un algorithme en production, tant que celui-ci fournit les meilleurs résultats possibles sur leurs problèmes concrets. En se confrontant aux meilleurs algorithmes classiques en production, les acteurs du quantiques peuvent alors avoir des points de comparaison solides et pertinents. Mieux encore, les équipes applicatives peuvent aider à la conception des futures générations de hardware, en s’appuyant sur des retours d’expérience concrets.
Au-delà de l’utilisation d’algorithmes sur les plateformes bruitées actuelles, la notion de développement conjoint entre le hardware et le software peut s’appliquer à long terme pour l’élaboration d’architectures avec codes de correction d’erreur. L’implémentation de procédures tout à fait générales risque sans doute d’induire des surcoûts prohibitifs pour le succès de la correction d’erreur. Il paraît de plus en plus nécessaire de travailler sur des procédures spécifiques, qui permettent de tirer parti des spécificités de chaque processeur. Des analyses fines des canaux d’erreur, des différents temps caractéristiques mis en jeu pour les mesures et les opérations logiques sont nécessaires pour calibrer le compromis entre l’application d’opérations logiques et les phases de correction active ou de mitigation d’erreur.
Références :
- [Arute] Arute, et al., Nature 574, 505 (2019)
- [Scholl] Scholl, et al., Nature 595, 233 (2021)
- [Schreiber] Schreiber, et al., Science 349, 842 (2015)
- [Thabet] Thabet, et al., ICLR submission (2022)
- [Zhong] Zhong, et al., Science 370, 6523 (2020)
Articles similaires :
 Physique quantique : de la recherche fondamentale au sujet industriel
Physique quantique : de la recherche fondamentale au sujet industriel
 Des labos de l’X au venture capital, bâtissons une industrie quantique
Des labos de l’X au venture capital, bâtissons une industrie quantique
 Des ingénieurs quantiques à Polytechnique : un défi pluridisciplinaire
Des ingénieurs quantiques à Polytechnique : un défi pluridisciplinaire
 BIG Quantum Hackathon : initiative française pour une diplomatie quantique
BIG Quantum Hackathon : initiative française pour une diplomatie quantique
 La souveraineté nationale au sein du plan national quantique
La souveraineté nationale au sein du plan national quantique