Mesurer l’information et la connaissance, rêve scientiste ou possibilité ?
L’insaisissable information contenue
Depuis de longues années la plupart des personnes, des entreprises, et des groupes humains, au moins dans les sociétés développées, manipulent en priorité de » l’information « , et accessoirement des produits. Cela donne lieu à d’innombrables efforts et contrats pour la maîtriser, c’est-à-dire pour la créer, l’acquérir, la stocker, la mettre en forme, la transmettre, la vendre, l’acheter, l’utiliser…
Mais l’information des uns n’est pas l’information des autres. Autant l’information des informaticiens et spécialistes des télécommunications est bien définie et mesurable, depuis en particulier les travaux de C. E. Shannon1, autant celle des professionnels d’autres domaines, par exemple des médias, des communicateurs, de monsieur Tout-le-monde, l’est mal, et ne peut que caricaturalement être mesurée en bits. Ceci parce que leur intérêt est bien sûr ailleurs, dans le contenu informationnel. . Nous pouvons souvent connaître le nombre de bits d’un message, mais pour beaucoup de créateurs et utilisateurs de l’information il représente très mal la quantité d’informations.
Y a‑t-il vraiment la même quantité d’informations dans ces 5 images que dans ces 50 pages de texte ou dans cette base de données de 500 enregistrements, qui nous renseignent sur le même sujet ? Un dessin ou une photo contiennent-ils plus ou moins qu’un long discours ? Ce programme de français des classes de seconde est-il trois fois plus copieux que celui des cinquièmes ? Ce journal télévisé en dit-il plus que ce journal quotidien imprimé ? Les connaissances de cette entreprise valent-elles deux, ou cent fois, celles de telle autre ?
Dans tous ces cas et bien d’autres, on ne sait en fait pas définir ce qu’est l’information contenue en jeu, et on sait donc encore moins en estimer la quantité. Des estimations même à 10 % près seraient un progrès considérable. Il n’est de science et d’économie que du mesurable, peut-on mesurer l’information contenue ? Pas le nombre de bits, mais la connaissance transmise qui est propre aux humains utilisateurs de l’information, par opposition aux machines courantes et même peut-être aux systèmes experts.
Mon ambition est de proposer une approche de solution, de méthode d’estimation. Elle peut apparaître insensée, scientiste, voire sacrilège – si j’en juge par l’accueil fait à ma proposition par divers interlocuteurs. La connaissance est dite insaisissable, c’est le propre des cerveaux humains, voire des dieux, et l’intelligence artificielle échoue à vouloir la codifier.
C’est bien vrai. Je ne prétends donc pas théoriser et décomposer l’information contenue ou la connaissance en éléments dénombrables, inaltérables, objectifs, et absolument mesurables. La connaissance reçue est en partie propre à la personne qui la reçoit, elle est donc subjective, dépend de ce que cette personne sait déjà, de son état physique et mental, et même de ses affects et sentiments. Mais je propose de réduire nos ambitions. Dans beaucoup de cas pratiques de transmission d’informations et connaissances, on peut juguler cette diversité, schématiser l’ensemble des récepteurs et les conditions de transmission du message, définir des restrictions d’usage, qui permettront de rendre objectives sous conditions les informations contenues et d’en estimer les quantités. Cela tout en laissant au cas informationnel (cas pratique ainsi schématisé) suffisamment de représentativité pour que la mesure de ces quantités d’informations soit utile et assez fiable pour satisfaire les intéressés à ce cas pratique.
Quelques conditions de la transmission de l’information numérisée
Par volonté délibérée, Shannon ne se préoccupe pas du contenu sémantique des messages, sa théorie traite de ce que nous appellerons le niveau 1, niveau numérisé de l’information.
Rappelons que cette théorie, que la tradition a retenue sous le nom de » théorie de l’information « , considère l’information comme ce qui renseigne un récepteur au sujet d’un émetteur-source2. Distinguons-en certains principes ou conditions que nous allons pouvoir réutiliser ensuite pour l’information contenue.
Shannon a signalé que la quantité d’informations reçues dépend certes beaucoup du message que l’émetteur a envoyé vers le récepteur, mais aussi des performances du canal de transmission qui les relie, et de ce que le récepteur sait déjà avant que la transmission ne commence. Il sait peut-être déjà le message (auquel cas il n’y a pas d’information transmise car il n’apprend rien sur la source). Il doit aussi connaître certains des codes que l’émetteur et le canal de transmission ont employés pour coder le message (s’il ne les sait pas, le message est pour lui incompréhensible ou irrecevable, il n’y pas non plus d’information transmise).
Ces trois conditions de la transmission (codes partagés, niveau d’ignorance préalable du message par le récepteur, performances du canal) nous guideront dans notre analyse aux niveaux de sens plus élevés que le niveau 1 traité par Shannon.
Le contenu et l’échelle du sens
L’information numérisée est tout à fait insuffisante pour la plupart de nos problèmes pratiques, non essentiellement techniques.
Ce qui compte pour M. Dupont au travail, c’est ce qu’il lit et comprend du tableau de gestion qu’il reçoit, pas les bits qui ont permis de le coder, transmettre et recevoir. Si on veut comparer les quantités d’informations d’un journal imprimé et du journal télévisé, il est tout à fait insuffisant de comparer le nombre de bits du fichier du journal tel qu’il peut exister chez l’imprimeur, et le nombre de bits du fichier de la bande vidéo numérique du 20 heures de TF N. Le fichier vidéo est beaucoup plus lourd en bits et pourtant M. Dupont sait peut-être déjà tout ce que le journal télévisé montre ou dit, par contre le journal imprimé est éventuellement plein pour lui d’autres révélations sur le moral de l’équipe de foot.
Mais comment définir le contenu ? Les bits sont bien un genre de contenu, mais de niveau de sens élémentaire, le niveau numérisé. Le moral de l’équipe de foot ne peut être apprécié que si on utilise des codes, des référentiels, beaucoup plus subtils. Cela va être la base de notre méthode : le contenu informationnel d’un message doit être apprécié par nous, qui cherchons à mesurer la quantité d’informations, simultanément à divers niveaux de sens, du plus simple (le 1er niveau, niveau numérisé) aux plus complexes (que nous appellerons niveau 4, des connaissances, et niveau 5, des savoirs). À chaque niveau correspondent des codes partagés entre récepteur et émetteur, ou parfois avec le canal.
Les trois conditions de Shannon, citées plus haut pour le niveau numérisé, sont si riches que nous allons pouvoir les transposer à des niveaux de sens qu’il s’était interdit de traiter3, mais notre but est pratique. Notre échelle du sens et une vision d’ingénieur, habitué aux approximations, vont nous permettre de l’approcher.
Un message sera porteur simultanément d’informations de plusieurs niveaux de sens, et donc de plusieurs quantités d’informations, une par niveau. Mais nous n’essaierons pas de mesurer la quantité d’informations globale ou de sens4 d’un message (ou d’un support) sur une sorte d’échelle universelle. Il faudrait pour cela disposer d’une équivalence entre nos unités de mesure à chaque niveau (une information de niveau élevé vaut n informations de niveau plus faible), ce qui n’a aucun sens, c’est le cas de le dire.
Pour définir ces niveaux de sens, poursuivons dans l’exemple du journal imprimé.
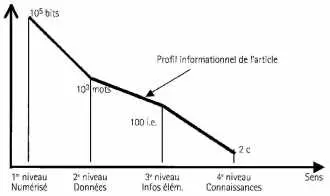
| Nombre d’informations de l’article lu par M. Dupont |
Déjà, pour lire le journal, il faut savoir lire. M. Dupont utilise donc les codes de la langue française écrite, et en premier l’alphabet des lettres françaises (avec des accents), en majuscules, minuscules, italiques…
Mais les caractères sont des signes qui n’apportent par eux-mêmes guère de sens à M. Dupont. Il faut monter un peu plus haut en sens pour définir un niveau 2 utile. M. Dupont utilise aussi le vocabulaire des mots français, tels que listés dans le dictionnaire (ou une partie de celui-ci, et il fait des erreurs) ; et un peu de vocabulaire anglo-américain car le journal en utilise, et pas mal de jargon sportif. Ce sera notre deuxième niveau, que nous baptiserons niveau des données. Pour déterminer combien un texte contient de données, nous comptons ses mots. Les nombres, si nombreux dans les bases de données de gestion par exemple, sont des sortes de mots.
C’est un niveau facilement mesurable, car on compte facilement les mots, à condition que les conventions soient claires (par exemple, un mot composé compte-t-il pour deux ou pour un ?).
Remarquons que M. Dupont ne reçoit comme informations ces mots5 que s’ils lui évoquent quelque chose. Et s’il ne savait pas déjà qu’il allait les trouver là : si par erreur un article répète deux fois de suite le même mot ou la même phrase, la deuxième occurrence ne lui apporte rien (sauf un éventuel renforcement). Et il ne reçoit les mots que si le canal est bon, ce qu’il ne serait pas si des mots étaient mal imprimés, ou si M. Dupont perdait une page avant de la lire. Les trois conditions nous servent donc aussi à ce niveau de sens, comme à tous les niveaux, pour analyser la quantité d’informations.
Au-delà des caractères et des mots, la langue française suppose encore l’emploi de sa grammaire, que M. Dupont doit partager au moins en partie avec l’émetteur et le canal (en particulier le journaliste et l’imprimeur). Ils n’en n’ont sûrement pas la même connaissance, et ils font chacun des erreurs, mais pas les mêmes. La grammaire concerne un peu le niveau 2 et beaucoup le niveau 3.
Il faut en effet qu’émetteur et récepteur partagent aussi la sémantique du texte, au sens de la linguistique6. Nous appellerons ce 3e niveau (de la sémantique) celui des informations élémentaires7 (i. e.). Dans cet exemple, c’est ce qu’une phrase8 lue communique à un lecteur parlant bien le français journalistique.
Ces quantités d’informations élémentaires auront un certain caractère objectif, si nous schématisons le cas et restreignons suffisamment les conditions de leur décompte :
- d’abord en simplifiant la grande diversité des récepteurs/lecteurs potentiels. Dans le cas pratique du journal, nous ne nous intéresserons souvent qu’au lecteur moyen, ou en tout cas à des types de lecteurs assez fréquents. On va faire des hypothèses en particulier sur ce que les lecteurs-types savent ou pas. Pour les cas informationnels dits parfaits au niveau N, ils sont réputés savoir les codes de ce niveau (ici au niveau 3, par exemple la grammaire), mais pas à l’avance le contenu du message à ce niveau ;
- ensuite en faisant des hypothèses simplificatrices sur la diversité des messages et des canaux : nous ignorerons sans doute – à moins que cela ne soit essentiel pour le cas – le numéro spécial annuel, le cas de grève de l’imprimerie qui force à réduire la taille du journal, la photo qui a été tronquée par erreur, etc. ;
- enfin en convenant, nous les mesureurs, ou plutôt les estimateurs de quantités d’informations pour ce cas, de certaines façons de les décompter qui simplifient l’estimation sans trop risquer de dénaturer le cas.
Les trois finalement sont des conventions de modélisation. Tout notre art va être de définir et adopter celles qu’il faut pour simplifier sans dénaturer le cas pratique, le modélisant ainsi en cas informationnel pour lequel nous parvenons à des quantités d’informations utiles et fiables pour le cas pratique.
On ne peut pas souvent exprimer simplement les conventions de décompte par des règles écrites, il vaudra mieux en donner des exemples pour des phrases typiques rencontrées dans le corpus à considérer.
Par exemple une phrase telle que » Le ministre de l’Intérieur, qui portait un costume noir, a décoré Zanutti de l’Ordre du Mérite sportif » comptera (en cas parfait) pour trois informations élémentaires plutôt qu’une. Les trois raisonnablement possibles sont :
- le ministre de l’Intérieur portait un costume noir,
- il a décoré Zanutti,
- la décoration était le Mérite sportif.
On pourrait en compter beaucoup plus (le ministre était celui de l’Intérieur. Il a agi. L’acte était de remettre quelque chose. Ce quelque chose était une décoration. Il n’y a qu’un ministre de l’Intérieur en France. Il a le pouvoir de décorer, etc.), mais ce serait contraire au bon sens, et notre M. Dupont moyen en fait ne les reçoit pas.
Ce niveau 3 sera souvent celui qui permet une analyse efficace du cas informationnel pratique : il est déjà bien sémantique (niveau de sens assez élevé), tout en permettant des évaluations assez reproductibles et pas trop complexes de quantités d’informations.
Mais on ne lit pas les phrases indépendamment les unes des autres, et l’ensemble d’un article communique un ou quelques messages principaux, intentionnels ou parfois non recherchés. Pour les émettre et les recevoir, on utilise des codes subtils, portant par exemple sur le monde du football. Le moral de l’équipe de foot est à zéro, et on va perdre le prochain match, ce sont les deux informations de haut niveau de sens que M. Dupont va inférer, faire émerger, retirer de l’ensemble de l’article, même si ce n’est pas littéralement exprimé ainsi. Appelons ce 4e niveau le niveau des connaissances. Pour communiquer ce message, il a fallu que le journaliste et M. Dupont partagent des connaissances générales sur le foot, et d’autres, par exemple la logique (si le journaliste a fait un syllogisme, il faut que M. Dupont ait compris), etc.
Au fur et à mesure que le niveau de sens considéré monte, il est évidemment de plus en plus difficile d’identifier les codes mis en jeu et de mesurer » objectivement » la quantité d’informations de ce niveau. L’art d’extraire les informations de niveau 4 d’un texte s’apparente à celui de faire des résumés. Pour pouvoir mesurer les quantités d’informations de ce niveau, nous devrons schématiser le cas et avoir recours à des estimateurs représentatifs de la population de récepteurs. Mais si nous arrivons à des estimations plausibles partageables par les divers estimateurs et utilisateurs de cette estimation, permettant d’éclairer des décisions à prendre avec un degré de confiance correct, cela nous suffira.
Alors, un message élaboré tel un article de journal imprimé peut être analysé dans un cas informationnel parfait sur 4 niveaux de sens, pour lesquels il présente un » Profil informationnel « . À chaque niveau de sens correspond une quantité d’informations dans des conditions modélisées d’émetteur, canal et récepteur. Un informaticien ou un télécommunicateur qui voudrait dimensionner les réseaux permettant de transmettre des articles s’intéressera aux niveaux 1 et 2. Un patron de média qui cherche pourquoi son journal est en perte de vitesse s’intéressera surtout aux niveaux 3 et 4 (voir graphique ci-dessus).
Cette analyse par niveau de sens permet d’identifier des caractéristiques intéressantes d’un texte. Sa densité informationnelle, sa concision peuvent être repérées par le rapport nombre d’informations élémentaires/nombre de mots ou par le nombre de connaissances/nombre de mots (ou d’informations élémentaires). Pour une transmission efficace, par exemple pour un enseignement, on a intérêt à ce que les débits de mots, d’informations élémentaires et de connaissances (mesurés par exemple sur chaque paragraphe en divisant la quantité par le temps que prend sa lecture ou présentation orale) soient à peu près constants au cours de la transmission9, avec peut-être une diminution en début d’après-midi et fin de journée car les récepteurs deviennent alors moins réceptifs, ce qu’on peut essayer de contrebalancer en diminuant la concision, etc.
Pour faire cette analyse, nous avons utilisé une structure d’analyse du message, sur les éléments de laquelle à chaque niveau nous avons décompté les informations : positions binaires, emplacements de mots, phrases, article entier. On devra ainsi pour chaque cas et chaque niveau non seulement définir l’unité employée, mais aussi l’élément de la structure d’analyse sur lequel on va compter élément par élément les informations, c’est-à-dire la granulométrie de l’analyse.
Examinons la suite de l’histoire du journal lu par M. Dupont. Au cours de cette lecture, celui-ci s’approprie les connaissances, en les déformant peut-être, et elles rejoignent et augmentent ses savoirs (ensembles de connaissances sur un domaine sans trou important), sa culture, elles contribuent à ses compétences (savoirs organisés en vue de l’action). Nous sommes là au 5e niveau de l’information, celui des savoirs.
Ce niveau pose des problèmes délicats. L’interaction avec le cerveau de M. Dupont y est dominante. L’apport de savoir que lui procure un message ne peut plus être mesuré sur le message, c’est une modification du récepteur qui se produit, et celui-ci est très complexe et unique. On ne peut guère définir et estimer cet apport que par différence entre les savoirs de M. Dupont avant et après arrivée du message. De nombreux tests cherchent à mesurer les savoirs d’une personne dans un domaine, et si pour des cas pratiques on a besoin de mesurer ce niveau, on ne pourra qu’avoir recours à de tels tests. Pour les compétences, l’estimation est basée en général sur le cursus de l’individu : il a fait telles études, il a telle expérience professionnelle et on en connaît telles preuves par ses réalisations…
L’échelle du sens que nous venons d’esquisser pour un article de journal peut être définie pour d’autres cas informationnels. On peut presque toujours modéliser le cas, définir les conventions, identifier les quatre premiers niveaux de sens, des unités de mesure de quantités d’informations pour chacun, et la structure d’analyse pour les estimer.
Par exemple, un cas intéressant est celui du journal télévisé regardé par le même M. Dupont.
Son niveau 1 (numérisé) peut être défini comme celui des bits de la bande son, et celui des pixels portés par les bandes des vidéos, qui arrivent plus ou moins dans le poste de télévision de M. Dupont. Son niveau 2 (données) pourrait être celui des phonèmes ou plus simplement des mots de la parole, et des images (assez faciles à compter) ou des formes montrées par la vidéo. Par exemple, il voit une forme humaine qui pose un objet sur une autre forme humaine. Au niveau 3 (informations élémentaires), celui porté par les phrases dites et les plans filmés, la même séquence visuelle lui montre le ministre de l’Intérieur qui décore le joueur Zanutti que M. Dupont reconnaît.
Ce niveau 3 permettra des comparaisons de cas assez différents, en particulier des comparaisons des nombres d’informations élémentaires portées par une image ou une séquence filmée et par un texte.
Le niveau 4 (connaissances) du journal télévisé est celui des enseignements et conclusions que M. Dupont en tire : Zanutti est vraiment bon, donc il a été décoré. Il permettra des comparaisons de cas très différents, mais les évaluations de quantités seront moins fiables.
Autre exemple, les formations prodiguées à des élèves et apprenants sont des cas dont l’analyse par niveau de sens est spécialement intéressante.
Le formateur veut en général transmettre des informations de niveaux 3, 4 et 5. Il envoie pour ce faire des messages et supports riches en niveaux 2 et 3 (textes, schémas, exposés). L’apprenant manque un certain nombre de ces informations, et reconstitue plus ou moins bien les informations de niveau élevé. Le formateur s’en aperçoit, et prodigue des messages complémentaires qui tentent d’expliciter au niveau 3 des informations de niveau 4, etc.
Bien sûr, les présentations de cas ci-dessus sont simplificatrices, de nombreuses questions vont se poser à chaque étape. Souvent les cas ne sont pas parfaits : les codes ne sont qu’incomplètement partagés, le récepteur n’ignore pas totalement les informations d’un certain niveau avant de les recevoir, le canal déforme.
La place manque pour en discuter ici. Mais je serai heureux d’envoyer des compléments et de discuter de cette méthode avec tout lecteur intéressé. Un travail considérable reste à faire pour l’adapter à des cas informationnels variés. Mais le jeu ne vaut-il pas la chandelle ?
_____________________________________________
1. Claude E. Shannon » The mathematical Theory of Communication » (Univ. of Illinois Press, 1949) (réédition d’articles parus dans Bell System Technical Journal, 1948). Traduction française : » Théorie mathématique de la communication « , par W. Weaver et C. E. Shannon (Retz-CEPL, 1975).
2. L’information est une notion première, que la théorie de l’information ne définit pas rigoureusement. Elle définit plutôt la quantité d’informations, comme la réduction du nombre de possibilités d’états de la source que le message permet au récepteur de décompter en bits. Le message peut être tout à fait involontaire. Par exemple, nous voyons la lumière réfléchie sur un objet, ce qui nous informe sur lui.
3. Shannon a dit que les aspects sémantiques de la communication ne concernaient pas le problème traité par sa théorie de l’information.
4. Fred I. Dretske (Knowledge and the flow of information, MIT Press 1981, réédité CSLI Publications, 1999) présente une extension des idées de Shannon en vue de mesurer la quantité d’informations et de connaissances à partir des probabilités de messages. Mais il montre que le sens d’un message ne peut être mesuré par sa probabilité a priori. Si votre voisin en région parisienne vous dit » il y a un gnou dans mon jardin » vous serez plus surpris que s’il vous dit » il y a un chat dans mon jardin « , les probabilités a priori sont très différentes, et pourtant ces phrases n’ont pas plus de sens l’une que l’autre – à condition que vous sachiez ce qu’est un gnou.
5. M. Dupont sait déjà les mots du dictionnaire, mais le message au niveau 2 est dans leur sélection.
6. La linguistique distingue souvent 4 niveaux d’analyse du discours : lexical (ou morphologique, qui n’est pas équivalent), syntaxique, sémantique, pragmatique. Le pragmatique, qui s’intéresse au sens de l’ensemble d’un texte, sera proche de notre niveau 4, alors que le sémantique est proche de notre niveau 3, et le lexical de notre niveau 2. » Sémantique » a aussi assez souvent une acception plus large qui relève à la fois de nos niveaux 2, 3, 4 et 5.
7. Ce niveau peut être appelé celui de la signification, du sens littéral, du sens linguistique, réservant alors le » sens » pour désigner le 4e niveau, » interprétation faite par un sujet donné dans un contexte » (Jean-Marie Pierrel, Ingénierie des langues, Hermès, 2000). Nous utilisons plutôt » sens » pour désigner toute l’échelle des sens croissants, de tous niveaux.
8. On pourrait choisir d’autres éléments supports de notre analyse d’information pour ce niveau que les phrases ; par exemple les propositions qui les constituent. Ou des éléments signifiants de types variés, tels les prédicats. La phrase a le mérite d’être une structure évidente du texte. Il y a certes des informations élémentaires qui sont portées par plusieurs phrases à la fois, on pourra les décompter aussi, ou les négliger. Notre comptage peut en effet rester approximatif.
9. On retrouve ainsi aux niveaux de sens élevés des caractéristiques bien connues au niveau numérisé.
Articles similaires :
 1848–1852, la République introuvable
1848–1852, la République introuvable
 Comment fonctionne la communication financière aux Etats-Unis
Les enjeux de l’informatique pour les malvoyants
Comment fonctionne la communication financière aux Etats-Unis
Les enjeux de l’informatique pour les malvoyants
 Pour une résolution simple de la conjecture de Kepler (Le dix-huitième problème de Hilbert)
L’Union européenne, le traité d’Amsterdam et les grands problèmes qui demeurent
Pour une résolution simple de la conjecture de Kepler (Le dix-huitième problème de Hilbert)
L’Union européenne, le traité d’Amsterdam et les grands problèmes qui demeurent